# Librerías
library(readxl) # Para leer los excels
library(dplyr) # Para tratamiento de dataframes
library(ggplot2) # Nice plots
library(Epi) # Para la ROC curve
library(caret) # para la confusion matrixRegresión Logística: salud
Introducción
En este cuaderno vamos a procesar un conjunto de datos mediante una Regresión Logística para discriminar el sexo de una persona a partir de los microdatos de la Encuesta Nacional de Salud. Resultados. Concretamente, se han tomado los datos relativos a 2017.
dataset
En este cuaderno vamos a analizar el dataset llamado salud.xlsx. Las variables de interés son las siguientes:
- EDAD: Identificación del adulto seleccionado: Edad.
- SEXO: Identificación del adulto seleccionado: Sexo. (1=Hombre, 2=Mujer)
- Altura: Altura en cm.
- Peso: Peso en kg.
Descripción del trabajo a realizar
Se pretende hacer una regresión logística que clasifique la variable respuesta Sexo en función de varios predictores, todos ellos continuos: Edad, Altura, Peso.
- Hacer un análisis exploratorio.
- IMPORTANTE: Convertir a factor las variables que lo sean.
- Plantear diversos modelos según variables incluidas.
- Compararlos con ANOVA y ROC CURVE.
- Para el modelo seleccionado, explicar los coeficientes, odds ratio,…
Análisis Exploratorio (EDA)
EDA viene del Inglés Exploratory Data Analysis y son los pasos relativos en los que se exploran las variables para tener una idea de que forma toma el dataset.
Cargar Librerías
Lo primero de todo vamos a cargar las librerías necesarias para ejecutar el resto del código del trabajo:
Lectura de datos
Ahora cargamos los datos del excel correspondientes a la pestaña “Datos” y vemos si hay algún NA o algún valor igual a 0 en nuestro dataset. Vemos que no han ningún NA (missing value) en el dataset luego no será necesario realizar ninguna técnica para imputar los missing values o borrar observaciones.
datos <- read_excel("../../../files/salud.xlsx", sheet = "Datos")# Creamos un gráfico de quesito o de sectores para ver qué proporción de personas ha mejorado su situación económica:
datos_quesito <- c(nrow(filter(datos, Sexo == "1")), nrow(filter(datos, Sexo == "2")))
etiquetas <- c("Hombre", "Mujer")
porcentajes <- paste0(round(datos_quesito / sum(datos_quesito) * 100, 1), "%")
colores <- c("lightgreen", "lightcoral")
pie(datos_quesito, labels = porcentajes, col = colores, radius = 1.05, cex = 1)
legend("topleft", etiquetas, cex = 0.7, fill = colores)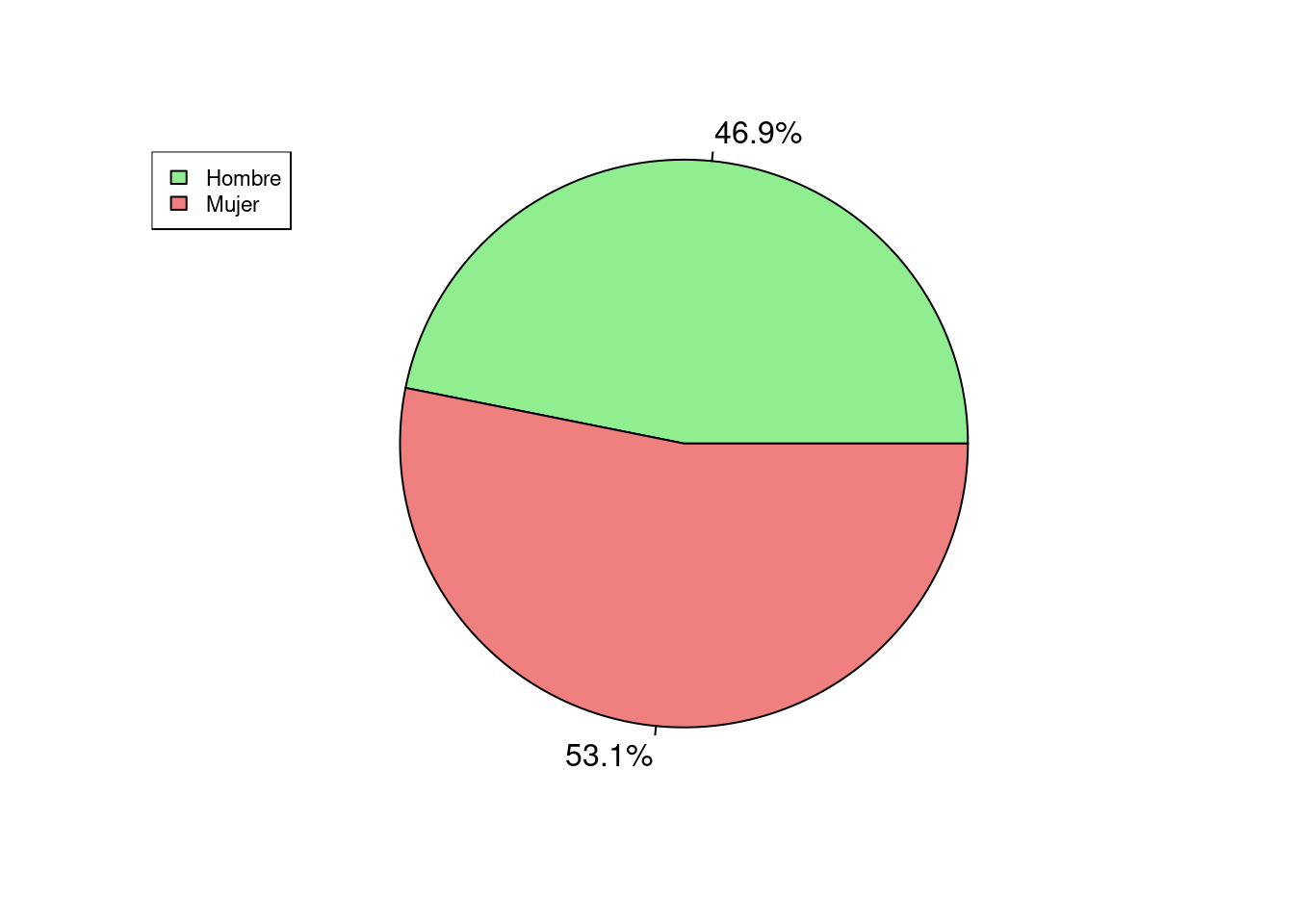
datos <- na.omit(datos)
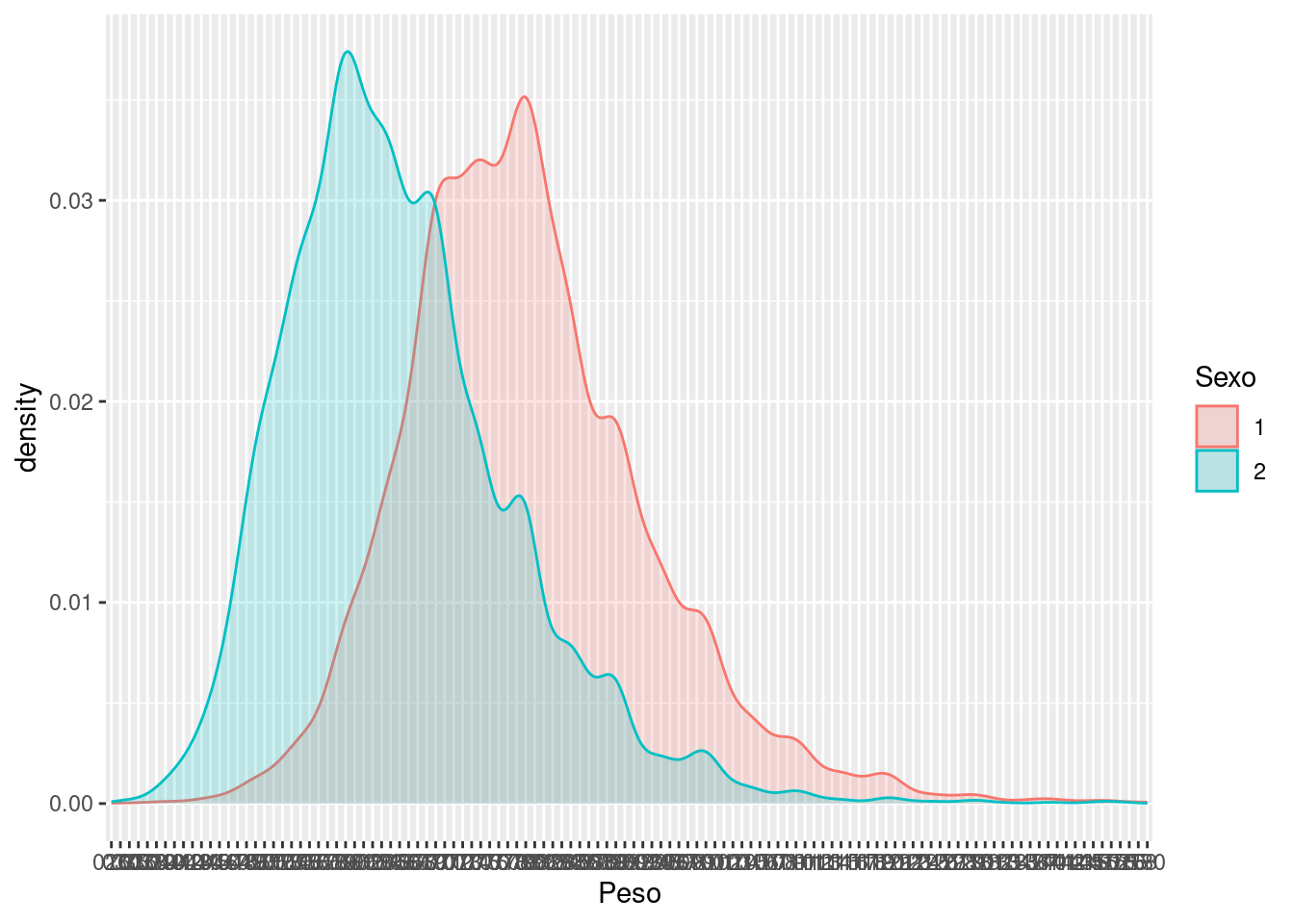
datos %>% ggplot(aes(x = Peso)) +
geom_density(aes(group = Sexo, colour = Sexo, fill = Sexo),
alpha = 0.2
)
datos <- na.omit(datos)
datos %>% ggplot(aes(x = Altura)) +
geom_density(
aes(
group = Sexo,
colour = Sexo,
fill = Sexo
),
alpha = 0.2
)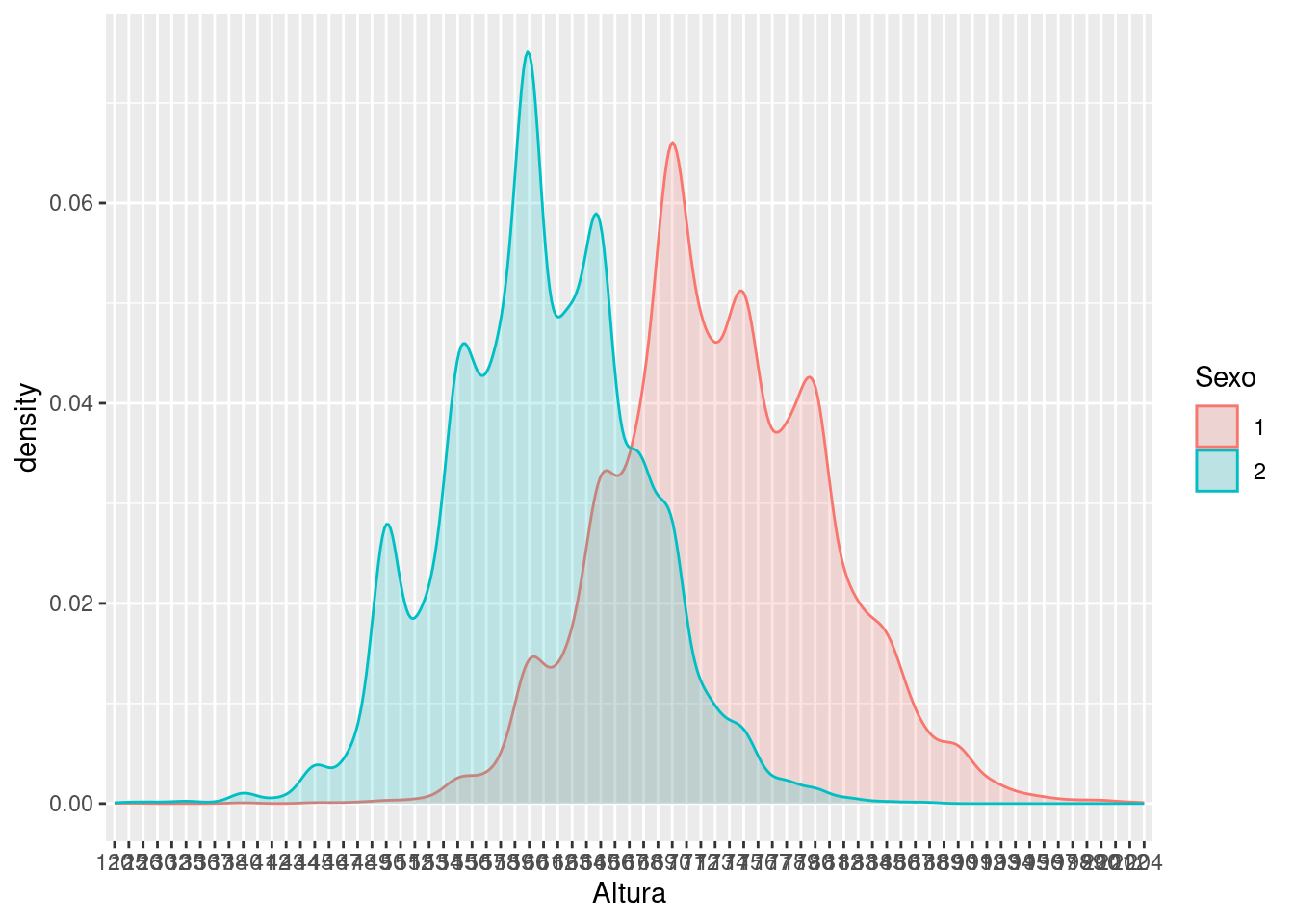
Vemos la distribución de la altura y el peso distinguiendo entre sexos, se observa como parte de su rango es común pero en los extremos de cada uno se puede distinguir con cierta facilidad si es Hombre/Mujer.
Clasificación: Regresión Logística
Introducción
Un análisis de regresión logística es una técnica estadística multivariante que tiene como finalidad clasificar las observaciones de una variable dependiente categórica a partir de una o varias variables independientes categóricas o continuas. Dichas variables independientes reciben el nombre de covariables. Asimismo, a diferencia de lo que suele hacerse cuando tenemos una variable respuesta continua, cuando esta es categórica, no interesa describir o pronosticar los valores concretos de dicha variable, sino la probabilidad de pertenecer a cada una de las categorías de la misma.
Aunque matemáticamente se pueda ajustar un modelo de regresión lineal clásico a la relación entre una variable dependiente categórica y una o varias covariables, cuando la variable dependiente es dicotómica (regresión logística binaria, caso más sencillo de regresión logística) no es apropiado utilizar un modelo de regresión lineal porque una variable dicotómica no se ajusta a una distribución normal, sino a una binomial. Ignorar esta cuestión podría llevar a obtener probabilidades imposibles: menores que cero o mayores que uno.
Para evitar este problema, es preferible utilizar funciones que realicen predicciones comprendidas entre un máximo y un mínimo. Una de estas funciones - posiblemente la más empleada - es la curva logística o función sigmoide:
\[\begin{align} \eta=\log \left(\frac{p}{1-p}\right)= \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots , \quad \text{with } \quad p=P(Y=1) \end{align}\]
Es decir, estamos estimando con una regresión lineal el valor de \(\eta\), que sí es una v.a. continua - a diferencia de Y que es binaria-.
Esto es, \(p=\frac{e^\eta}{1+e^\eta}=\frac{1}{1+e^{-\eta}}\). De esta forma, para valores positivos muy grandes de \(\eta\) llamado odds, \(e^{-\eta}\) es aproximadamente cero, por lo que el valor de la función es 1; mientras que para valores negativos muy grandes de \(\eta\), \(e^{-\eta}\) tiende a infinito, haciendo que el valor de la función sea 0.
A continuación, para simplificar un poco las cosas, consideremos el modelo de regresión logística más sencillo: regresión logística binaria simple (una sola covariable):
[ P(Y=1)= ]
La interpretación de esta función es muy similar a la de una regresión lineal: el coeficiente \(\beta_0\) representa la posición de la curva sobre el eje horizontal o de abscisas (más hacia la izquierda o más hacia la derecha); mientras que \(\beta_1\) representa la pendiente de la curva, es decir, cuán inclinada está en su parte central (cuanto más inclinada, mayor capacidad de discriminar entre los dos valores de la variable dependiente).
Ejemplo sencillo Vamos a mostrar como una variable binaria no tiene sentido predecirla con una Regresión Lineal sino Logística.
# Generación de datos para el ejemplo
set.seed(123)
n <- 200
Altura <- rnorm(n, mean = 165, sd = 10)
# Crear una variable binaria 'Sexo' en función de Altura
Sexo <- as.factor(ifelse(Altura + rnorm(n) > 165, 1, 0))
datos_ejemplo <- data.frame(Altura, Sexo)
# Regresión lineal
modelo_lineal <- lm(Sexo ~ Altura, data = datos_ejemplo)
# Regresión logística
modelo_logistico <- glm(Sexo ~ Altura, data = datos_ejemplo, family = binomial)
# Regresión Lineal
par(mfrow = c(1, 2))
plot(datos_ejemplo$Altura, datos_ejemplo$Sexo, col = "lightblue", main = "Ajuste por Regresión Lineal")
abline(modelo_lineal, col = "navy")
# Regresión Logística
plot(datos_ejemplo$Altura, as.numeric(datos_ejemplo$Sexo) - 1, col = "lightblue", main = "Regresión Logística", xlab = "Altura", ylab = "Sexo")
curve(predict(modelo_logistico, data.frame(Altura = x), type = "response"), add = TRUE, col = "navy", lwd = 2)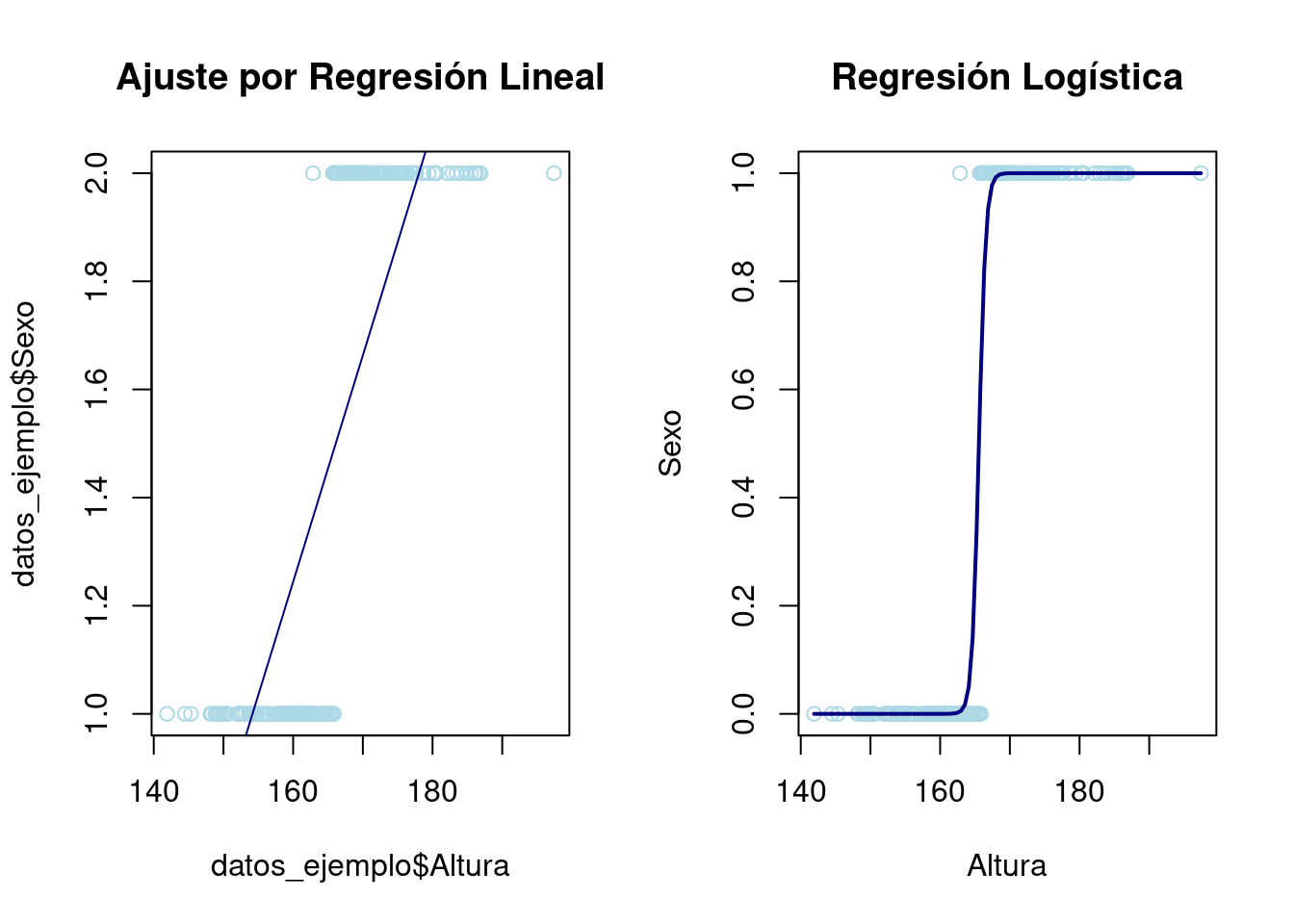
En este ejemplo, se muestra cómo un ajuste por regresión lineal no se adapta bien a datos binarios, produciendo predicciones que pueden ser mayores que 1 o menores que 0. En cambio, la regresión logística produce una curva en forma de S que se adapta mejor a los datos, con predicciones que están siempre entre 0 y 1. Esto demuestra que para problemas de clasificación binaria, la regresión logística es una mejor opción que la regresión lineal.
Bondad de Ajuste e Interpretación Modelo
Interpretación Modelo
Recordar que el modelo tomaba la forma \[\eta=\log \left(\frac{p}{1-p}\right)= \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots , \quad \text{with } \quad p=P(Y=1)\], es decir, estamos estimando el log(odds). Esto nos lleva a las siguientes apreciaciones:
Aunque tanto \(P(Y=1)\), como \(Odds(Y=1)\), como \(Logit(Y=1)\) expresan la misma idea, están en distinta escala:
- La probabilidad toma valores comprendidos entre 0 y 1.
- La odds tiene un valor mínimo de cero y no tiene máximo.
- La logit o log(odds) no tiene ni mínimo ni máximo.
Por ejemplo, a una probabilidad de 0,5, le corresponde una odds de 1 y un logit de 0. Ahora bien, es cierto que razonar en términos de cambios en los logaritmos resulta poco intuitivo. Por ello, es preferible interpretar el cambio en las odds o en la razón de ventajas (también llamada odds ratio, razón de probabilidades o razón de momios).
La interpretación más frecuente es interpretar los signos de los coeficientes del modelo, es decir, los signos de \(\beta_1, \ldots , \beta_k\).
Si \(\beta_i >0\) , se traduce en que un aumento de una unidad en la variable \(x_i\) -si es continua- o un cambio de categoría -si \(x_i\) es categórica- se traduce en un aumento de \(\beta_i\) unidades el valor de logit. Es decir, la probabilidad \(p\) (que Y=1) aumenta, en función de \[p=\frac{e^\eta}{1+e^\eta}\].
- Si \(\beta_i <0\) , se traduce en que un aumento de una unidad en la variable \(x_i\) -si es continua- o un cambio de categoría -si \(x_i\) es categórica- se traduce en una disminución de \(\beta_i\) unidades el valor de logit. Es decir, la probabilidad \(p\) (que Y=1) disminuye, en función de \[p=\frac{e^\eta}{1+e^\eta}\].
Una pregunta importante en cualquier análisis de regresión es si el modelo propuesto se ajusta adecuadamente a los datos, lo que conduce naturalmente a la noción de una prueba formal para la falta de ajuste (o bondad de ajuste).
Medidas Especifidad y Sensibilidad
La especificidad y la sensibilidad son medidas utilizadas para evaluar el rendimiento de un modelo predictivo, especialmente en problemas de clasificación binaria (donde solo hay dos clases). Las definimos como:
- Sensibilidad (Sensitivity): Es la proporción de verdaderos positivos (casos positivos correctamente identificados) respecto al total de casos positivos reales. Es la capacidad del modelo para identificar correctamente los casos positivos.
- Especificidad (Specificity): Es la proporción de verdaderos negativos (casos negativos correctamente identificados) respecto al total de casos negativos reales. Representa la capacidad del modelo para identificar correctamente los casos negativos.
Un equilibrio entre ambas es deseable, pero depende del contexto específico del problema y de las consecuencias de los falsos positivos y falsos negativos. En el caso, por ejemplo, de detectar si un paciente tiene cáncer o no, parece más razonable centrarse en los Falsos Negativos, ya que un paciente que tiene cáncer no lo estamos detectando, lo que lleva un riesgo implícito muy alto.
| Clasificado como Positivo | Clasificado como Negativo | Total | |
|---|---|---|---|
| Realmente Positivo | Verdadero Positivo (VP) | Falso Negativo (FN) | VP + FN |
| Realmente Negativo | Falso Positivo (FP) | Verdadero Negativo (VN) | FP + VN |
| Total | VP + FP | FN + VN |
Sensibilidad ( )
Especificidad: ( )
Curva ROC
La curva ROC es una representación gráfica de la sensibilidad frente a la tasa de falsos positivos a varios umbrales de clasificación. Se utiliza comúnmente en análisis de clasificación para evaluar el rendimiento de un modelo.
Para calcular el área bajo la curva ROC (AUC-ROC), se utiliza la tasa de falsos positivos y de falsos negativos. Cuanto más cerca esté el AUC-ROC de 1, mejor será el rendimiento del modelo, ya que indica una mayor capacidad de distinguir entre clases.
Es una medida de bondad porque evalúa qué tan bien puede discriminar un modelo entre las clases positivas y negativas. Cuanto más se acerque el AUC a 1, mejor será la capacidad del modelo para distinguir entre las clases. Se utiliza para comparar y seleccionar modelos, donde un AUC mayor indica un mejor rendimiento predictivo.
Modelo
Formulación
IMPORTANTE: Convertir a factor las variables que tengan que ser tratadas como tal, de lo contrario R las tratará como numéricas. Además, la variable respuesta debe tener los niveles codificados como \(0\) y \(1\) para poder usar la función glm. El resto de variables convertirlas a numéricas en caso de que aplique.
datos$Edad <- as.numeric(datos$Edad)
datos$Altura <- as.numeric(datos$Altura)
datos$Peso <- as.numeric(datos$Peso)
# Pasar factores a 0=Hombre y 1=Mujer
datos$Sexo <- ifelse(datos$Sexo == "1", "0", "1")
datos$Sexo <- as.factor(datos$Sexo)
# Ver resumen de datos y ver si hay NA
summary(datos) Edad Sexo Altura Peso
Min. : 15.00 0:10318 Min. :120.0 Min. : 26.00
1st Qu.: 39.00 1:11701 1st Qu.:160.0 1st Qu.: 62.00
Median : 52.00 Median :166.0 Median : 71.00
Mean : 52.84 Mean :166.7 Mean : 72.66
3rd Qu.: 67.00 3rd Qu.:173.0 3rd Qu.: 81.00
Max. :103.00 Max. :204.0 Max. :180.00 sum(is.na(datos))[1] 0datos <- na.omit(datos)Como hemos visto que había na’s en el conjunto de datos, los quitamos para que no haya posibles problemas (eliminamos esas observaciones).
Vemos que si hay algún
A continuación presentamos tres posibles modelos y posteriormente elegiremos uno de ellos.
- lmod1 : Queremos clasificar la Sexo en función de la edad de la persona (numérica).
- lmod2 : Queremos clasificar la Sexo en función de la edad de la persona (numérica) y el Altura (numérica).
- lmod3 : Queremos clasificar la Sexo en función de la edad de la persona (numérica), el Altura (numérica) y el Peso (numérica).
# lmod1
lmod1 <- glm(formula = Sexo ~ Edad, family = binomial(link = logit), data = datos)
summary(lmod1)
Call:
glm(formula = Sexo ~ Edad, family = binomial(link = logit), data = datos)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.1957973 0.0407321 -4.807 1.53e-06 ***
Edad 0.0060933 0.0007289 8.359 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30438 on 22018 degrees of freedom
Residual deviance: 30368 on 22017 degrees of freedom
AIC: 30372
Number of Fisher Scoring iterations: 3# lmod2
lmod2 <- glm(formula = Sexo ~ Edad + Altura, family = binomial(link = logit), data = datos)
summary(lmod2)
Call:
glm(formula = Sexo ~ Edad + Altura, family = binomial(link = logit),
data = datos)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 49.432554 0.659059 75.00 <2e-16 ***
Edad -0.032589 0.001136 -28.68 <2e-16 ***
Altura -0.285114 0.003782 -75.39 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30438 on 22018 degrees of freedom
Residual deviance: 17225 on 22016 degrees of freedom
AIC: 17231
Number of Fisher Scoring iterations: 5# lmod3
lmod3 <- glm(formula = Sexo ~ Edad + Altura + Peso, family = binomial(link = logit), data = datos)
summary(lmod3)
Call:
glm(formula = Sexo ~ Edad + Altura + Peso, family = binomial(link = logit),
data = datos)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 47.518534 0.667448 71.19 <2e-16 ***
Edad -0.027013 0.001172 -23.04 <2e-16 ***
Altura -0.258429 0.003886 -66.50 <2e-16 ***
Peso -0.039144 0.001624 -24.11 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30438 on 22018 degrees of freedom
Residual deviance: 16605 on 22015 degrees of freedom
AIC: 16613
Number of Fisher Scoring iterations: 6En este caso, el Modelo 3 tiene el AIC más bajo, lo que sugiere que podría ser el mejor ajuste entre los tres modelos. Sin embargo, es importante considerar otros aspectos y realizar pruebas adicionales si es necesario para validar el modelo seleccionado. Por otro lado, en términos de la Deviance podemos ver cosas parecidas.
Para este modelo vamos a calcular la matriz de confusión y el área ROC. Hemos calculado la matriz de confusión utilizando un threshold de 0.5. Es decir, si hay mas de un 0.51 de probabilidad de que una observación pertenezca a la clase 1 (Mujer), entonces lo clasificamos como tal.
Luego veremos el valor óptimo para este threshold.
# confusion matrices
predicted2 <- predict(lmod3, datos[, c("Edad", "Altura", "Peso")], type = "response")
confusionMatrix(data = as.factor(ifelse(predicted2 > 0.5, 1, 0)), reference = datos$Sexo, positive = "1")Realicemos ahora la curva ROC con la función ROC del paquete Epi.
ROC(form = Sexo ~ Edad + Altura + Peso, data = datos, plot = "ROC", lwd = 3, cex = 1.5)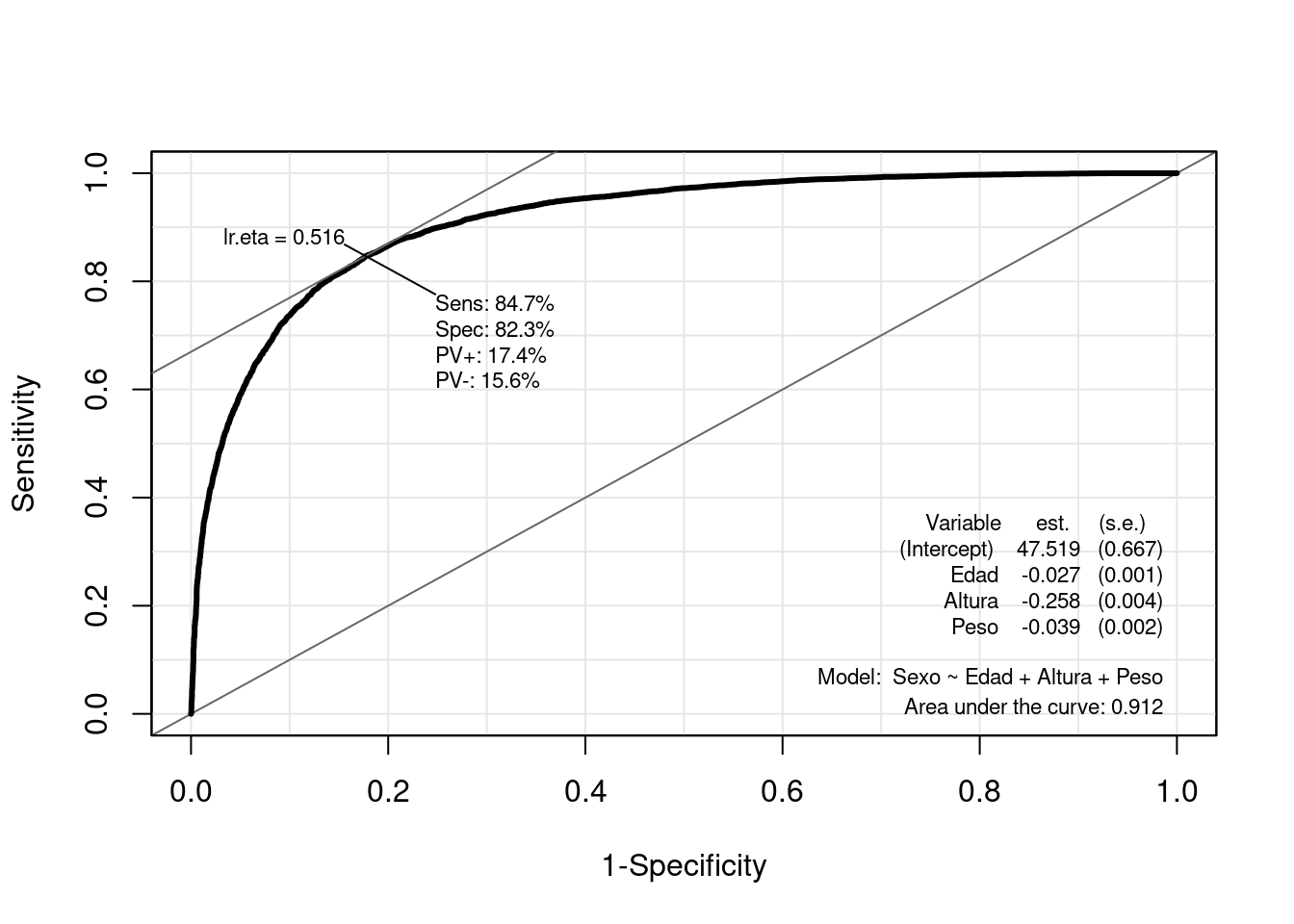
Observamos una Especifidad del 82% y una Sensibilidad del 84%. Esto quiere decir que nuestro modelo es mejor evitando falsos negativos, que falsos positivos.
Destacar que el elemento Ir.eta que aparece arriba, es el punto de corte óptimo (threshold óptimo) de la probabilidad. Es decir, si nuestra regresión logística predice que hay una probabilidad mayor de \(0.516\) de que una observación sea mujer, entonces la clasificaremos como tal.
Podemos usar el presente modelo para predecir la probabilidad de ser mujer en función de las variables predictoras de nuevas observaciones.
Interpretación coeficientes
Vamos a volver a sacar el summary del modelo para proceder a explicar todo bien de nuevo.
summary(lmod3)
Call:
glm(formula = Sexo ~ Edad + Altura + Peso, family = binomial(link = logit),
data = datos)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 47.518534 0.667448 71.19 <2e-16 ***
Edad -0.027013 0.001172 -23.04 <2e-16 ***
Altura -0.258429 0.003886 -66.50 <2e-16 ***
Peso -0.039144 0.001624 -24.11 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30438 on 22018 degrees of freedom
Residual deviance: 16605 on 22015 degrees of freedom
AIC: 16613
Number of Fisher Scoring iterations: 6Edad: Por cada incremento unitario en la edad, el logaritmo de odds de éxito en Sexo disminuye aproximadamente en 0.027, manteniendo constante el resto de variables.
Altura: Por cada incremento unitario en la altura, el logaritmo de odds de éxito en Sexo disminuye aproximadamente en 0.25, manteniendo constante el resto de variables.
Peso: Por cada incremento unitario en el peso, el logaritmo de odds de éxito en Sexo disminuye aproximadamente en 0.039, manteniendo constante el resto de variables.
Interpretación coeficiente Edad
Vemos que este coeficiente es relativamente pequeño, con lo cual no parece tener impacto en el \(Sexo\) de la persona. Esto tiene sentido ya que el número de niños/niñas nacidos cada año tiende al 50%-50% con lo cual no debería haber más elementos de una subpoblación conforme aumente/disminuya la edad.
Es verdad, que conforme aumenta la edad, la mortalidad es más grave en hombres, pero en ningún caso para producir tantas defunciones como para posibilitar la discriminación del Sexo en función de la edad.
Interpretación coeficiente Peso
El coeficiente para Peso, tiene un valor negativo. Esto implica que la probabilidad de clasificar a una observación como mujer disminuye conforme aumenta la variable Peso (manteniendo el resto de variables constantes). Esto parece razonable ya que dentro de un mismo grupo de edad, incluso de altura, los hombres tienden generalmente a ser más corpulentos que las mujeres y por tanto a pesar más. De todas maneras sería la combinación Peso/Altura la que nos ayudaría a discriminar bien.
Interpretación coeficiente Altura
El coeficiente para Altura, tiene un valor negativo. Esto implica que la probabilidad de clasificar a una observación como mujer disminuye conforme aumenta la variable altura (manteniendo el resto de variables constantes). Esto parece razonable ya que dentro de un mismo grupo de edad, incluso de peso, los hombres tienden generalmente a ser más altos que las mujeres. De todas maneras sería la combinación Peso/Altura la que nos ayudaría a discriminar bien.
Conclusión
Aquí se han explicado los supuestos de la regresión logística con un dataset en el que se pretende clasificar la variable respuesta Sexo en función de varios predictores continuos: Edad, Altura y Peso. La evidencia nos ha mostrado que la combinación de estas variables tienen un poder predictivo significativo para determinar el sexo de los individuos. Este modelo permite identificar patrones y diferencias clave entre las características físicas de hombres y mujeres, proporcionando una herramienta útil para clasificaciones y análisis en estudios demográficos y de salud.